
Greater than 2 minutes, my friend!
“Oh, and please make sure you use the same terms as in the screenshots” Easily extract the plain text from all images in an MS Word document at once
Last week a translator called me… After she had accepted the job, her customer asked her to make sure the terms she uses in the translation are the same as in the screenshots; the software would not be localized. At first, she thought: “OK, no problem. I’ll see the screenshot and I’ll use the same English terms. No big deal”. Then she realized there were an awful lot of screenshots (242!), containing a lot of terms and phrases; both were used throughout the 80 page manual (counted text only).
If I would get a question like this from a language service provider (LSP), I would not be surprised. I would figure out how to deal with it and propose an automated solution. LSPs appreciate some automation as they often get similar requests and when they solve a problem, they can be smarter than their competitors and they can also send good jobs to the freelance translators. This translator however did not work for an LSP and she did not need a full blown, nicely integrated technical solution. Just an answer to the question “how do I do this? Do you know a simple, cheap and fast solution?”
This is what I advised.
- Extract all images from the word document. This is easy:
- Make a copy of the word document
- Rename the copy: replace .DOCX by .ZIP
- Open the ZIP file and go to the sub folder: word
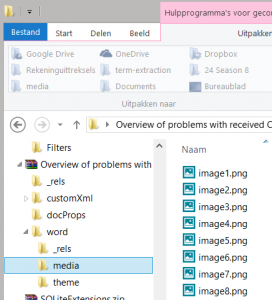
- Extract the sub folder media to your desktop
- Close the zip file and open the media folder on your desktop: here you’ll find all screenshots (PNG or other format)
- Extract the text from these images using a free online OCR tool
- newocr.com: upload your files one by one, but you can select what needs to be OCR’d. The result is really OK.
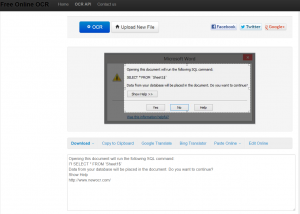
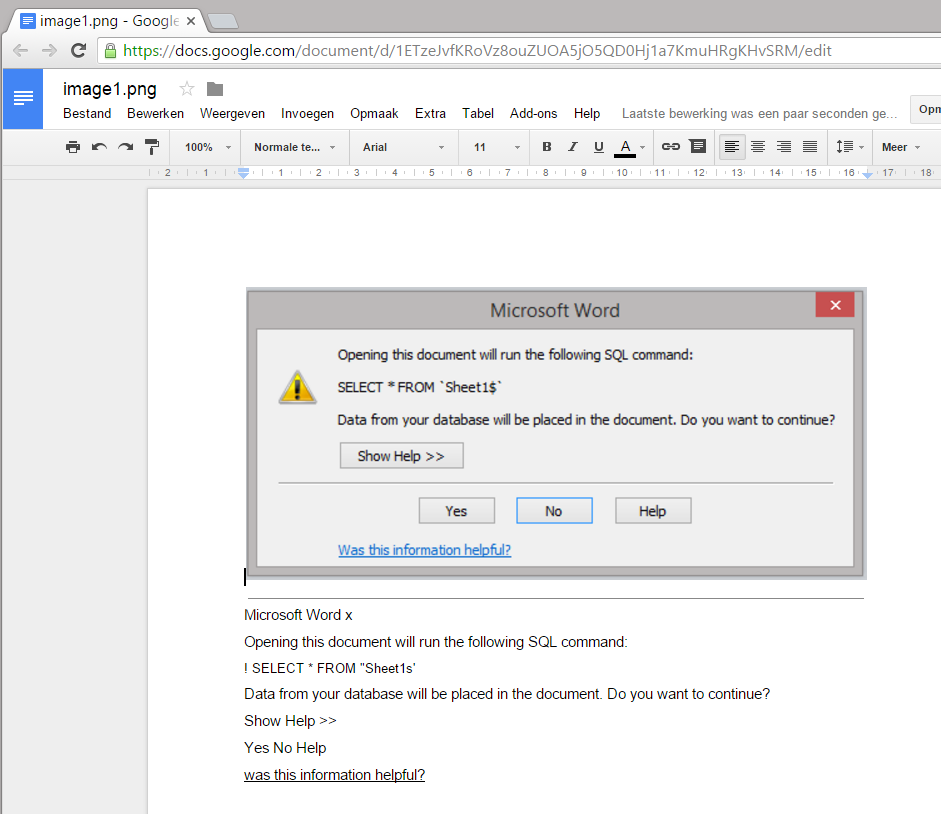
- drive.google.com: upload the whole folder at once to Google Drive. In Google Drive select the desired file, right-click on it to open it in “Google Docs” from “Open with” submenu. Now your file will opened and OCR’d at once. You can select, copy, change… the extracted text.
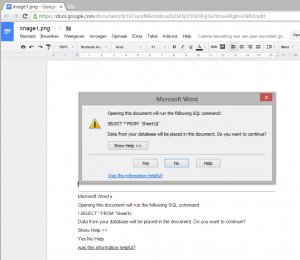
Download the document again to your local drive using “Download as” from File menu in the desired format. Select the Plain Text format.
- newocr.com: upload your files one by one, but you can select what needs to be OCR’d. The result is really OK.
- Import the extracted text in your CAT tool. It depends on the CAT you’re using how you have to do this and what you can do with this, but there are 2 ways to test what works best for you (and know that one solution does not exclude the other):
- Import it as terminology in your terminology database as non-translatable terms;
- Import it as a translation memory (source-source); If you want to create a source-source TM, any alignment tool that creates TMX will do this. Don’t forget to give the right name (language code) to the target “source”. So your target may be “FR” while you actually import “EN”;
- If you’re not happy with the result, contact the support team of your CAT tool. They may know a better trick.

Maybe you can use this advice as well one day.



Great advice. I like to deliver great jobs to freelancers. The ZIPping hint is just to good. Thank you.
Thank you, a great help!
Thank you Gert, this is really useful!
Hi Gert, this is great advice. Thank you.
Would you have any idea about how to go about running a PDF through OCR, and then being able to highlight and mark up the post-OCR PDF document, treating the PDF as a revise-able rough draft?
Kye, as you know PDF is not really made to edit, especially if the PDF just contains images, not characters/text. There are way though to work with PDF in a smart way. I’ll try to give an overview of the tools and tricks I use next week.
If you have Adobe Acrobat (not Reader), you can save the PDF as Word docx format and then use the same process described above.
This is great! Thanks for sharing.
Thank you !!!!
Excellent – that is going to come in handy later this week!
Hi Gert, Interesting post. I have already used the unzipping trick for several years. It can be particularly useful on PPTX files as well. But the sore point is the OCR, I did some tests today with the tools indicated by you, but also with Abby and they all required a lot of fixing. So might I suggest transcription as an alternative. memoQ 2015 offers a neat system for importing and transcribing graphics from Office files and then adding them to the translation project where they can be “copy-sourced” for a TM or Termbase, or obviously translated.
Good to know, Juliet. Thanks for letting me know.
When you run an OCR tool, make sure the language settings are correct. When your settings are on English and you process a French file, the results will be disappointing. But even when the language setting is correct, the OCR can create crap. Some fonts (especially those that support ligatures) make the document hard to OCR. Also when the resolution is low ( < 150 dpi) or the fonts are small ( < 8pt) OCR is hard.
As a Localisation specialist, I often need to extract text from images to add to a Translation memory. If you do not have to extract text from too many images, please note that Microsoft OneNote comes with built-in OCR capability which is pretty accurate. Just press Windows key + S to copy any area of your screen, paste the resulting image into OneNote, right click on it and select “Copy Text from Picture”.
Simples!
James, great new knowledge for me. I never used Notes. Maybe it’s time I look at this tool that has been sleeping on my hard disk for 10 years.
Thanks for sharing this tip.
Sounds great James, I must try it too. It is the short bits of text that are tricky for OCR I think. When one has whole sentences or paragraphs, modern tools are usually pretty good, indeed Studio 2015 can be brilliant, but its the single words or phrases from a screenshot or labels in a graphic which are quite a test.
Will now try OneNote.
Thanks.
Juliet
Thank you!
Thank you for posting this Gert Van Assche, very helpful article and I will try the zip trick next time I am working on a project with a lot of images.
Great information Gert!
I hate this kind of jobs, but this makes it really easy!
I tried this out and Google Drive only lets me open one image at a time with Google Docs. If I select more than one image file, the “Open with…” menu does not have the Google Docs option. How do you open multiple at once? Thanks!
Eva, I checked this and that does indeed not work (anymore?). I think I should remove the (s) in my blog.