
Greater than 4 minutes, my friend!
Extracting terms from an English PDF file The development path of a tool like PdfTermCrawler
There are 2 things I always do before I start to develop a tool:
- Figure out if no similar tool already exists
- Getting some certainty that the tool will have a positive impact on people’s lives
Usually I get triggered by a customer, talking about his project, or while having lunch together: I rarely meet customers who can describe in detail the tool they need, but they can describe the problems they are running into. Before I started to work on the PdfTermCrawler a customer told me this story:
We received a project where we had to translate about 100 documents. We would get the original format at the start of the project, but for now we only received PDFs. As this was a new customer, we had to figure out what was the relationship between all files. We could tell from the pictures that they were in the same domain, but as translators work with words, we wanted to know how much work it would be for them. We could extract text from all the files, create a huge project in our CAT, do a pseudo-translate and figure out how much inter-document and intra-document re-use there would be, but 1. that would cost a lot of time and 2. it would not tell us if our translators would be able to translate it. As all documents had to be translated in just a couple of weeks, we wanted to understand the terminology used in all those documents. Was it comparable? Could we make a term-list for all translators to use prior to kicking of the translation work? Because we could not figure this out, we decided not to take on the project.
That was the story.
I looked around and did not find a tool that could extract terms from PDF files. There were tools that extract text. And there were tools that find terms in text. I gave both tools to my customer, and he would have been happy with the result if processing would not have been so cumbersome. Then I knew that one tool would have been a better solution. I could make a mini-pipeline connecting the two: the output of the first one had to flow into the second one.
So I started to evaluate the two main components:
- I asked my customer if the translators were happy with the extracted terms: “Yes. About half of them were useful.”
- Were the components open source or freeware, or if I would pay for them could I distribute them myself embedded in another tool? I wrote to the developer of the component I had doubts about and he replied: “Yes.”
- Could I run them on my server? Developing an online service has the advantage I don’t need to worry about distributing an executable AND every Win/Mac/Linux users can use it.
- The PDF2TXT component exists for Apache but the conversion takes a long time, users are forced to upload their PDF and if it contains High-Res images, it goes wrong. So I decide that the tool I’ll make will run on a local windows machine, not on a server.
- To run the term extraction on the PC, people have to install the right version of Python first. Too many things can go wrong. So I decide that I’ll organize the term extraction on a server.
- What do translators do when they run into unknown terms? a dictionary lookup! So it would be nice if I could add automatic term lookup as well, or a link to Google search or Wikipedia.
What are the things I need to figure out next?
- How to send plain text to the server — As the extracted text can be quite long, I decided to upload the text file via FTP to a web server.
- How to make sure the user gets his termlist — Delivery over HTTP would require the user to keep a connection open, so I decided delivery via MAIL would be best.
- Can I create a frequency based TERM-cloud that allows translators to do a quick term search in many dictionaries at once? All tools I found create word clouds, not term clouds. How to I prevent a word cloud tool to split multi-word terms in single words?
Now development could start. I started to use XOJO but I ran into problems with FTP. So I switched to LUA (via AMS, a RAD tool I used a lot till 3 years ago). LUA does not support UNICODE, but as my tool would only work on English (for extracting terms), that limitation is nothing to worry about. The server side is done in PHP. The help is written in HTML (online) and embedded into the tool. To create a term-cloud I need to pre-process the term list and post-process them at display time.
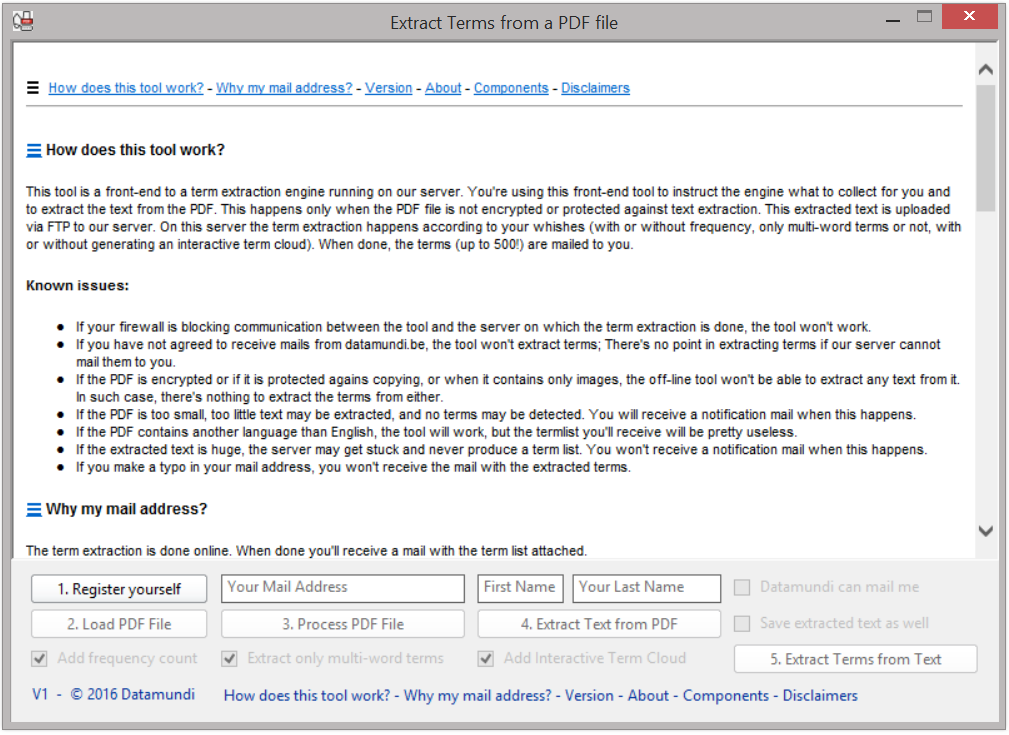
When the development was done, I asked my 9 year old daughter to test it. She does not speak English and she does not know what the tool should do, but she does love Minecraft 😉 I only want to see that she can get from the start to the finish without me helping her. It would be pretty dumb to have a tool that can push a file through a pipe-line, but the user gets stuck half way due to a sloppy user interface. The test was useful: today I had to redesign the UI. I added numbers on the buttons, changed the order, and when a step was successful the button gets disabled and the next one gets enabled. This way only one button is clickable at a time.
Now the tool is done, I want to share it with you. This is not something I usually do. I always write tools for a customer and only one customer uses the tool. I only need to support one customer. If he needs a bug to be fixed, if he needs an extra feature, I can do it because there’s only him to consider. Yet I decided I spent too much time in development for me not to share this tool. Would you like to test and use this tool? Download it for free from my site. I hope it serves you one day.
Please contact me if you have questions or suggestions. — thanks.




Downloaded! Thank you so much, Gert!
Very nice Gert – and thanks for the quick help!
Free tool to EXTRACT TERMS FROM PDF version 2 released:
– You only needs to register once.
– Tips added about removing passwords and extracting terms from many PDF files at once.
– An interactive-table view and a terms-in-context view are now generated as well.
– If the extracted text is not recognised as English, you’ll be warned about this.
– You can remove the job from the server by clicking on a link in the mail.
link to datamundi.be
Very interesting! I’d love to be able to run this locally, personally, since I’m comfortable with Python and the command-line. Is this open source?
Jonathan, no it isn’t (my code is dirty and in XOJO — as it is a spin-off of something I wrote for a customer I cannot share it). But the components I used are all open source. This is specified in the documentation. I must say I’m not always happy with the extracted terms: sometimes the important ones are not extracted and too many useless ones are extracted. The reason is that all term extraction tools were created for other reasons than creating a termbase for translators. I hope this info helps nevertheless.